Observation 1: Imbalanced Annotations
Although each clean class has the same amount of images, the number of human annotations for each clean category varies.
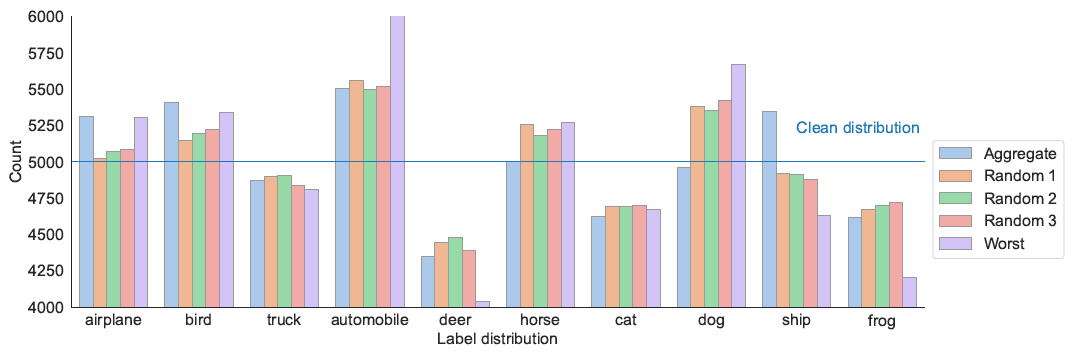
Although each clean class has the same amount of images, the number of human annotations for each clean category varies.
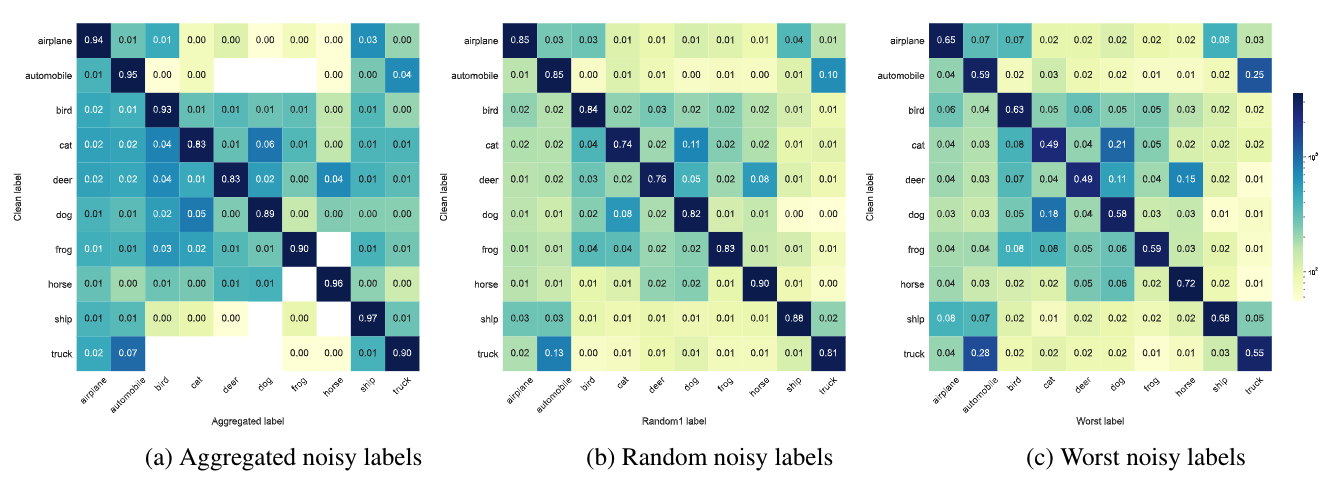
In the class-dependent label noise setting, noise transition matrices of CIFAR-10N and CIFAR-100N follow a more complex pattern.
The figure below visualizes transition matrices of CIFAR-10N noisy labels (color bar is log-norm transformed).
When the label dimension is high, i.e., CIFAR-100 which contains 100 classes, a frequent phenomenon appears:
one image may contain multiple classes which further lead to a new "co-exist" noise label pattern.
Here are some exemplary CIFAR-100 training images with multiple labels.
The text below each picture denotes the CIFAR-100 clean label (first row), and the human annotated noisy label (second row).

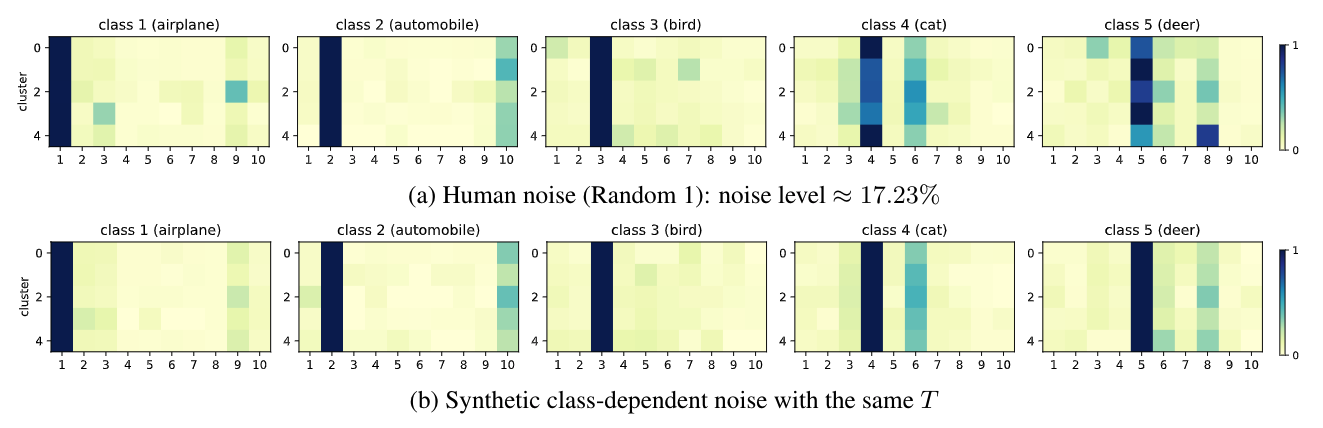
The figure below depicts noise transitions of human-level label noise and the synthetic version. We divide the representations of images from the same true class into 5 clusters by k-means. The representations come from the output before the final fully-connected layer of ResNet34. The model is trained on clean CIFAR-10. Negative cosine similarity measures the distance between features.
For Human noise (a), different rows of each visualized matrix exist more differences than that of synthetic class-dependent noise.
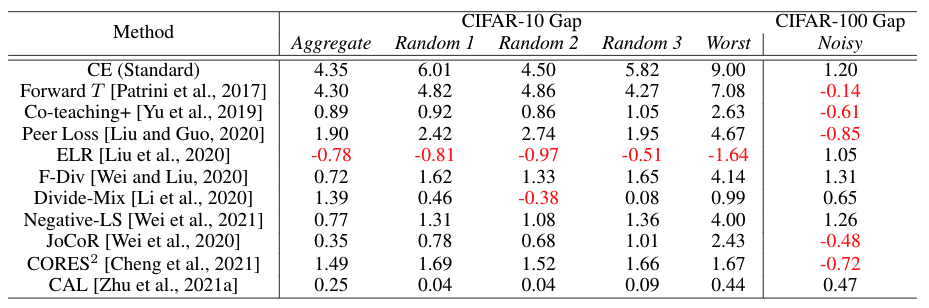
We also reproduce several methods on synthetic noisy CIFAR datasets generated by exactly the same noise transition matrices of CIFAR-N.
In the table below, we highlight that for most selected methods, class-dependent synthetic noise is much easier to learn on CIFAR-10, especially when the noise level is high. The gap is less obvious for CIFAR-100.
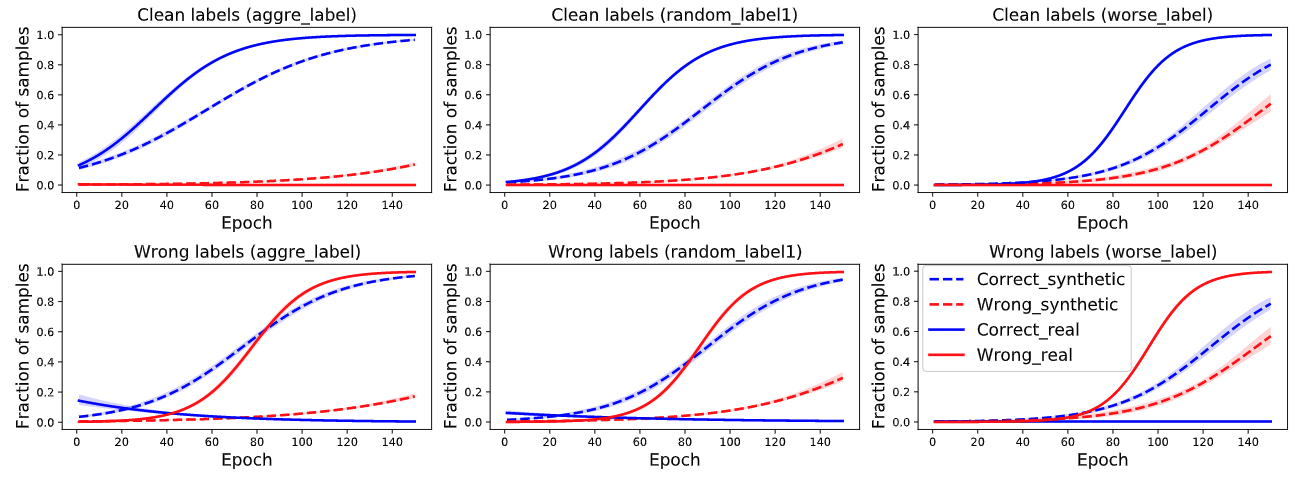
The figure below shows the memorization of clean and wrongs labels on CIFAR-10N and synthetic noise with same T: red line denotes the percentage of memorized (wrongly predicted) samples, blue line denotes that of correctly predicted ones.
It is obvious that models trained on synthetic noise and human noise have different memorizing behavior:
Learning with synthetic noisy labels will make the model memorizes both correct and wrong predictions;
Learning with human noisy labels will make the model only memorizes correct predictions on clean labels and wrong predictions on wrong labels.